Scientific Data will be a forum for publications about datasets, but will not be a repository for primary datasets. Primary data associated with Data Descriptors will be stored in one or more external data repositories. Why this distinction?
This strategy helps us draw some clear lines around the goals of Scientific Data. By ensuring that the primary datasets are stored in external systems, we make it crystal clear that our goal is to help authors publish content that promotes the scientific value and reusability of their datasets, not to control access to data. We feel that this is a progressive strategy that will help promote collaboration and data consolidation, rather than fragmentation.
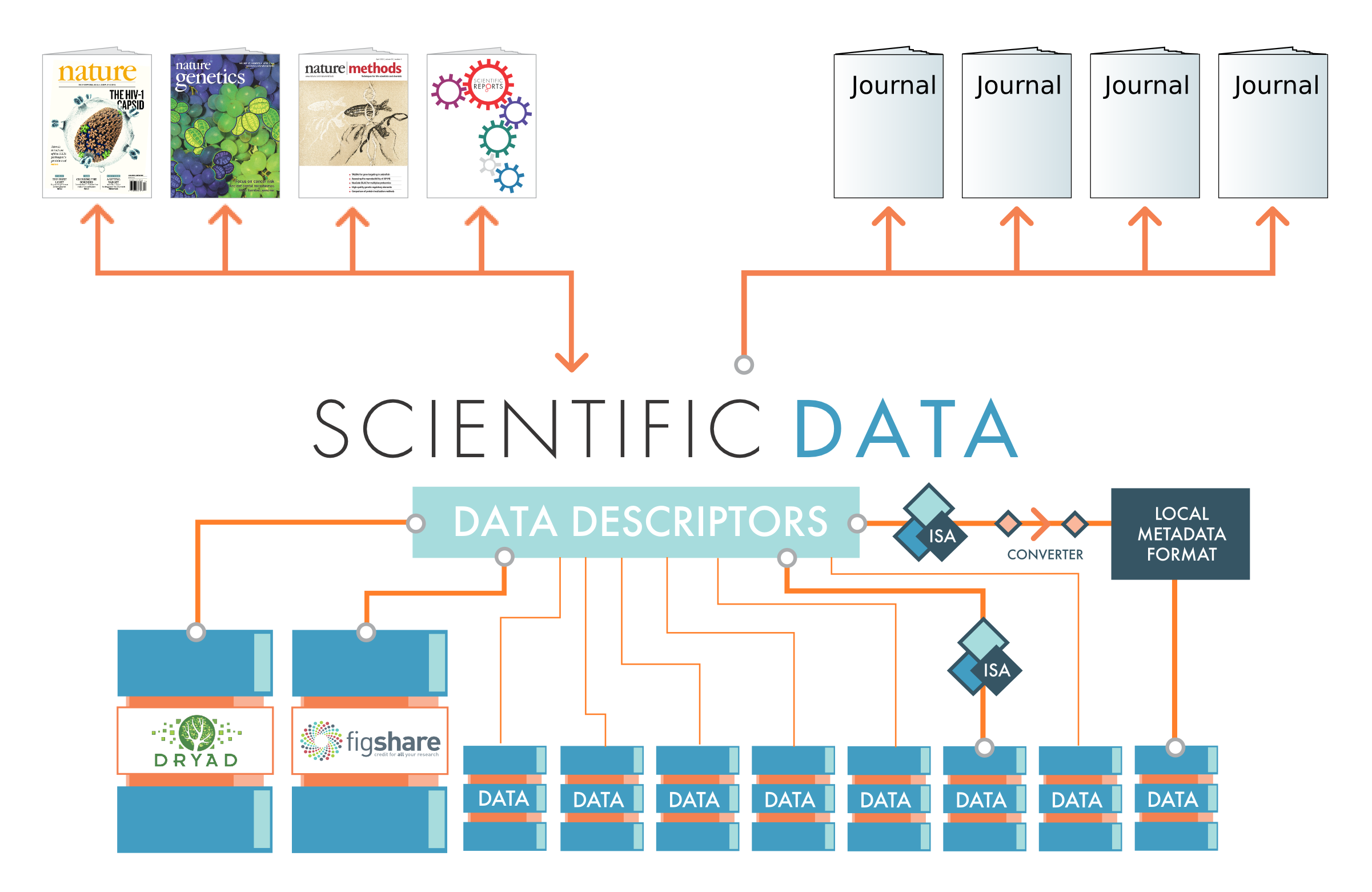
Publicly available scientific data is located in many different repositories, making it hard to find relevant datasets (aka the “data silo” problem). Scientific Data will provide a searchable publication platform where researchers can find high-quality datasets across many different data repositories. Data Descriptor publications will be linked to related research publications at Nature Publishing Group journals and external publishers, allowing scientists to navigate easily between research findings, rich data descriptions, and the actual data. We are working with two generalist repositories, Dryad and figshare, so that all datasets will have a home, and plan to develop metadata transfer pipelines with other repositories using the ISA framework.
Existing scientific data repositories play a leading role in defining standards and promoting data sharing. For many data-types, model organisms, diseases or domains of study, excellent community data repositories already exist. We are working with repository representatives to make sure that Scientific Data will complement and enhance these important services, by providing:
- A publication platform for detailed methods descriptions and technical validation information
- Data search and discovery features that reach across diverse repositories
- Peer-review of data release
- The career credit that is duly associated with rigorously peer-reviewed publications
In parallel, we are working with Dryad and figshare, two “generalist” scientific repositories, to ensure that all data-types will have a home. Even when good data-type specific repositories exist, they will be available as “fallback repositories,” helping us put datasets through peer review if the existing repositories do not support confidential peer review or happen to be down for maintenance. Authors would then be expected to move their data to the community standard repository before publication.
Ultimately, we believe that journal-specific data repositories are not the answer to promoting open data sharing. Research journals already store a wide range of datasets in their supplementary material sections. This is much better than not releasing the data, but it is widely regarded as a terrible place to store primary datasets. Indeed, the Nature-titled journals already have strong policies that require data deposition to public repositories in fields where standards and repositories are well-established. Journal-specific data repositories risk muddying these important policies.
In line with this strategy, our main content type, the Data Descriptor, is designed to complement the information in both research journal articles and at data repositories. Data Descriptors will provide detailed descriptions of the experiments and procedures involved in generating important datasets, including essential information needed for scientists to assess the technical quality of the data, reproduce key methods or analysis workflows, and ultimately reuse the data to address important research questions. In addition, every publication at Scientific Data will be supported by metadata describing key properties of the experiments and resulting data, which will be checked by an in-house curator and released in the ISA-tab format, and hopefully other standard formats in the future. These metadata will aid data mining, and will help scientists find and reuse high-quality datasets stored across multiple data repositories.